For up-to-date articles, tutorials and other resources, visit LearnCloudNative.comThis blog is not being maintained anymore.
Kubernetes master and worker nodes
A Kubernetes cluster is a set of physical or virtual machines and other infrastructure resources that are needed to run your containerized applications. Each machine in a Kubernetes cluster is called a node.
A Kubernetes cluster is a set of physical or virtual machines and other infrastructure resources that are needed to run your containerized applications. Each machine in a Kubernetes cluster is called a node. There are two types of node in each Kubernetes cluster:
- Master node(s): this node hosts the Kubernetes control plane and manages the cluster
- Worker node(s): runs your containerized applications
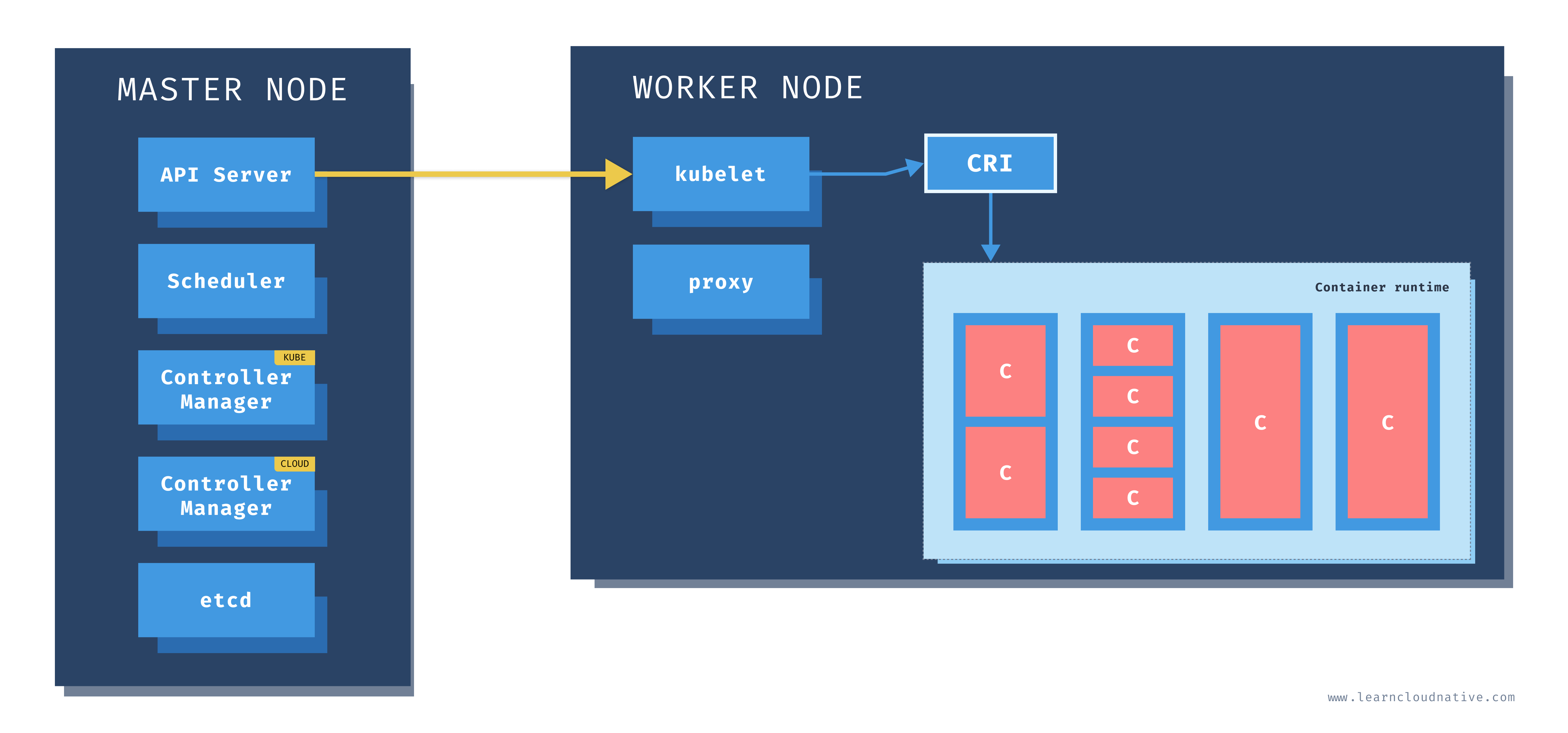
Master node
One of the main components on the master node is called the API server. The API server is the endpoint that Kubernetes CLI (kubectl) talks to when you're creating Kubernetes resources or managing the cluster.
The scheduler component works together with the API server to schedule the applications or workloads on to the worker nodes. It also knows about resources that are available on the nodes as well as the resources requested by the workloads. Using this information it can decide which worker nodes your workloads end up on.
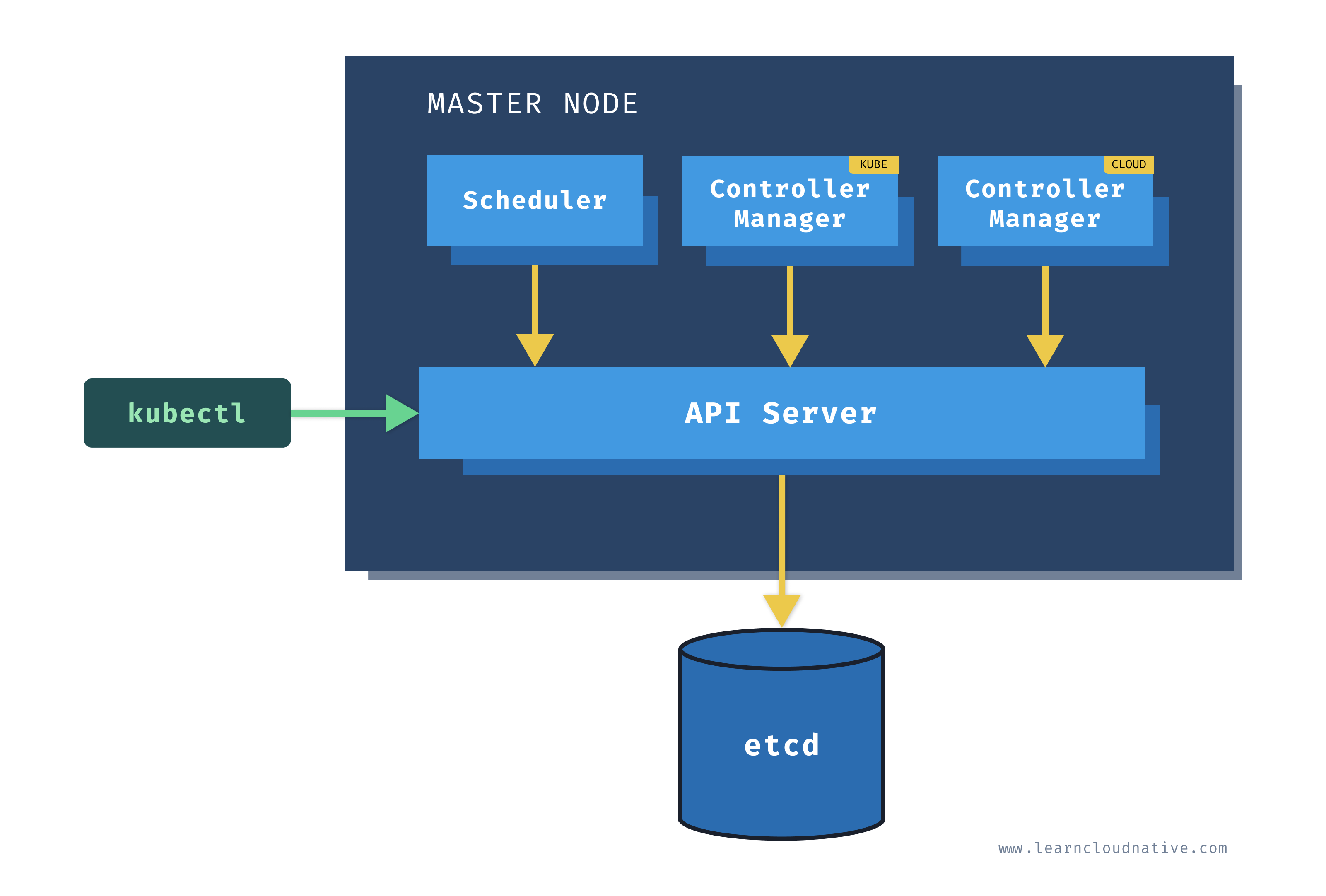
There are two types of controller managers running on master nodes.
The kube controller manager runs multiple controller processes. These controllers watch the state of the cluster and try to reconcile the current state of the cluster (e.g. "5 running replicas of workload A") with the desired state (e.g "I want 10 running replicas of workload A"). The controllers include a node controller, replication controller, endpoints controller, and service account and token controllers.
The cloud controller manager runs controllers that are specific to the cloud provider and can manage resources outside of your cluster. This controller only runs if your Kubernetes cluster is running in the cloud. If you're running Kubernetes cluster on your computer, this controller won't be running. The purpose of this controller is for the cluster to talk to the cloud providers to manage the nodes, load balancers, or routes.
Finally, etcd is a distributed key-value store. The state of the Kubernetes cluster and the API objects is stored in the etcd.
Worker node
Just like on the master node, worker nodes have different components running as well. The first one is the kubelet. This service runs on each worker node and its job is to manage the container. It makes sure containers are running and healthy and it connects back to the control plane. Kubelet talks to the API server and it is responsible for managing resources on the node it's running on.
When a new worker node is added to the cluster, the kubelet introduces itself and provides the resources it has (e.g. "I have X CPU and Y memory"). Then, it asks if any containers need to be run. You can think of the kubelet as a worker node manager.
Kubelet uses the container runtime interface (CRI) to talk to the container runtime. The container runtime is responsible for working with the containers. In addition to Docker, Kubernetes also supports other container runtimes, such as containerd or cri-o.
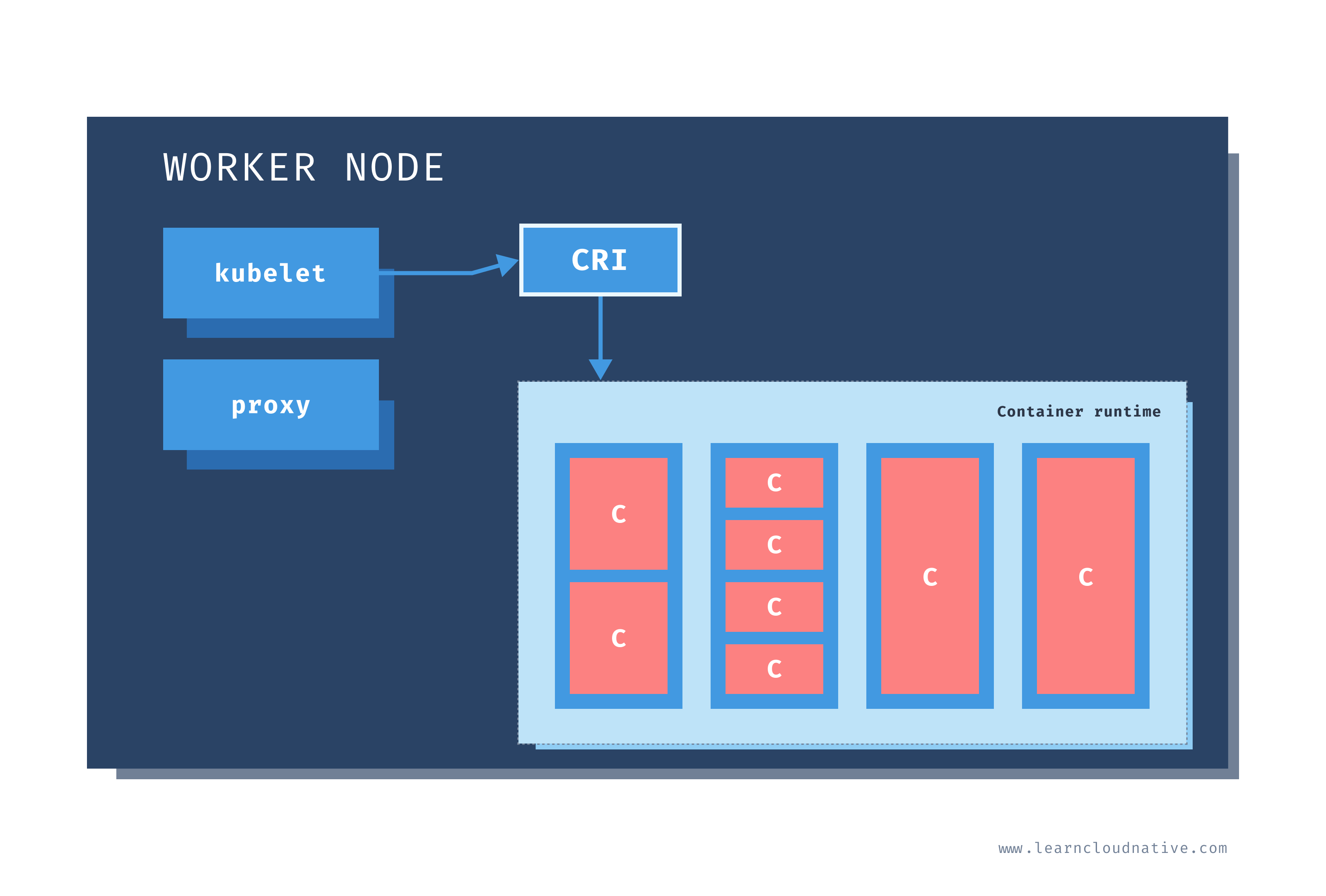
The containers are running inside pods, represented by the blue rectangles in the above figure (containers are the red rectangles inside each pod). A pod is the smallest deployable unit that can be created, schedule, and managed on a Kubernetes cluster. A pod is a logical collection of containers that make up your application. The containers running inside the same pod also share the network and storage space.
Each worker node also has a proxy that acts as a network proxy and a load balancer for workloads running on the worker nodes. Client requests that are coming through an external load balancer are redirected to containers running inside the pod through these proxies.